
# cat /etc/services[命令] Linux 命令 ps (显示进程) (转载)
ps 命令的使用
Ps命令是Linux中最常使用的进程查看工具,主要用于显示包含当前运行的各进程完整信息的静态快照(查看静态的进程统计信息)。通过不同的命令选项可以有选择性的查看进程信息。
a:显示当前终端下的所有进行信息,包括其他用户的进程。与x选项结合时将显示系统中所有的进程信息。
u:使用以用户为主的格式输出进程信息。
x:显示当前用户在所有终端下的进程信息。
-e:显示系统内的所有进程信息。
-l:使用长格式显示进程信息。
-f:使用完整的格式显示进程信息。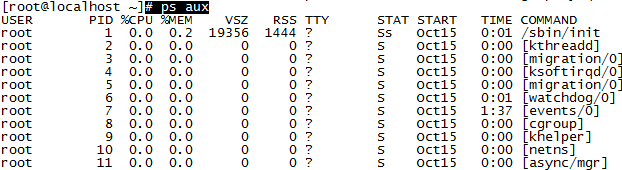
# ps aux
解释:
USER:启动该进程的用户账号名称
PID:该进程在系统中的数字ID号,在当前系统中是唯一的。
TTY:表明该进程在哪个终端上运行。“?”表示未知或者不需要终端。
STAT:显示了进程当前的状态,如S(休眠)、R(运行)、Z(僵死)、<(高优先级)、N(低优先级)、s(父进程)、+(前台进程)。对于僵死的进程,应该手动处理掉。(问:为什么?)
START:启动该进程的时间
TIME:该进程占用CPU的时间
COMMAND:启用该进程的命令名称
%CPU:CPU占用百分比
%MEM:内存占用百分比
VSZ:占用虚拟内存(swap空间)大小
RSS:占用常驻空间(物理内存)的大小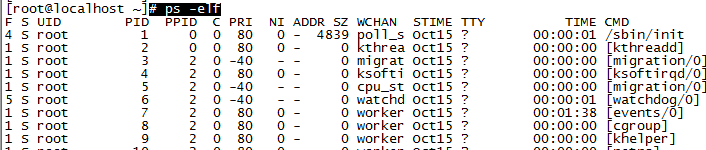
————————————————
版权声明:本文为CSDN博主「秃头阿鑫」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_47763101/java/article/details/106391154注明:所有转载内容皆直接从被转载文章网页的标题和内容的文本和图片中复制而来

站主补充:
补充一:D 状态的进程
D 状态的进程代表处于不可以被杀死的休眠状态。D 状态的进程就算是用 kill -9 命令也无法杀死
补充二:将 ps 的输出工整
# ps -T
补充三:ps 显示 SELinux 的上下文标签
# ps -M
或者:
# ps -Z
[命令] Linux 命令 usermod (修改用户)
案例一:修改某 1 个用户的 uid
# usermod -u 1005 zhumingyu(补充:这里以将用户 zhumingyu 的 uid 修改为 1005 为例)
案例二:修改某 1 个用户的备注
# usermod -c "admin zhumingyu" zhumingyu(补充:这里以将用户 zhumingyu 的备注修改为 admin zhumingyu 为例)
案例三:修改某 1 个用户的运行环境
# usermod -s /sbin/nologin zhumingyu(补充:这里以将用户 zhumingyu 的执行环境修改为 /sbin/nologin 为例)
案例四:修改某 1 个用户的家目录
# useradd -d /home/zhumingyu zhumingyu(补充:这里以将用户 zhumingyu 的家目录修改为 /home/zhumingyu 为例)
案例五:修改某 1 个用户的主要所属组,以名称的方式
# usermod -g root zhumingyu(补充:这里以将用户 zhumingyu 的主要组修改为组 root 为例)
案例六:修改某 1 个用户的主要所属组,以 gid 的方式
# usermod -g 1200 zhumingyu(补充:这里以将用户 zhumingyu 的主要所属组的 gid 修改为 1200 为例)
案例七:修改某 1 个用户的附属所属组
7.1 修改某 1 个用户的附属所属组
# usermod -G root zhumingyu(补充:这里以将用户 zhumingyu 的附属所属组修改为组 root 为例)
(注意:此用户的附属所属组会同时包含组 root 和组 zhumingyu,其它的附属所属组会被删除)
7.2 查看某个组里有哪些个用户
# getent group root或者:
# cat /etc/group | grep root(补充:这里以查看 root 组里有哪些用户为例)
案例八:给用户添加组
8.1 给某 1 个用户添加 1 个附属所属组
8.1.1 给某 1 个用户添加 1 个附属所属组
# usermod -a -G root zhumingyu或者:
# usermod -aG root zhumingyu(补充:这里以给用户 zhumingyu 的附属所属组里添加 1 个组 root 为例)
8.1.2 查看某个组里有哪些个用户
# getent group root或者:
# cat /etc/group | grep root(补充:这里以查看 root 组里有哪些用户为例)
8.2 给某 1 个用户添加多个附属所属组
8.2.1 给某 1 个用户添加多个附属所属组
# usermod -a -G root,zhumingyu1 zhumingyu或者:
# usermod -a -G root,zhumingyu1 zhumingyu(补充:这里以给用户 zhumingyu 的附属所属组里添加组 root 和组 zhumingyu1 为例)
8.2.2 查看某个组里有哪些个用户
# getent group root或者:
# cat /etc/group | grep root(补充:这里以查看 root 组里有哪些用户为例)
案例九:清空用户的密码并禁止其使用密码登录
# usermod -p 'SSH_KEY_ONLY' zhumingyu(补充:这里以清空用户 zhumingyu 的密码并禁止其使用密码登录为例)
案例十:锁住用户
# usermod -L zhumingyu或者:
# usermod --lock zhumingyu(补充:这里以锁住用户 zhumingyu 为例)
案例十一:解锁用户
# usermod -U zhumingyu或者:
# usermod --unlock zhumingyu(补充:这里以解锁用户 zhumingyu 为例)
[命令] Linux 命令 userdel (删除用户)
内容一:只是删除用户
# userdel <user>内容二:删除用户的同时还要删除家目录
# userdel -r <user>补充一:RHEL 系统自带标准用户参考
https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/5/html/deployment_guide/s1-users-groups-standard-users
https://access.redhat.com/solutions/225183
补充二:RHEL 系统自带标准组参考
https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/5/html/deployment_guide/s1-users-groups-standard-groups
[命令] Linux 命令 useradd (创建用户)
内容一:用户种类的介绍
1) UID 从 200 到 999 的是系统用户
2) UID 大于 1000 的是普通用户
(注意:如果创建用户时没有特意说明,则 uid 是会随即产生的)
内容二:useradd 命令选项
2.1 useradd 普通选项
1) -c 或者 –comment 添加备注
2) -d 或者 –home-dir 指定家目录
3) -f 或者 –inactive 设置密码的失效时间
4) -m 或者 –create-home 设置家目录
5) -M 或者 –no-create-home 不设置家目录
6) -u 或者 –uid 指定 UID
7) -s 或者 –shell 执行环境
8) -g 或者 –gid 指定主组或者 GID
9) -G 或者 –groups 指定从组
10) -p 或者 –password 设置密码
2.2 useradd 特殊选项
-D 显示或设置创建用户的默认参数
(
补充:
1) 当只使用 -D 特殊选项时则显示创建用户的默认参数
2) 当在 -D 特殊选项后面再添加普通选项时,则设置创建用户的默认参数
)
内容二: 用户创建命令 useradd 的使用案例
2.1 案例一:显示创建用户的默认参数
# useradd -D2.2 案例二:设置创建用户的默认密码有效期
# useradd -D -f 15 zhumingyu(补充:这里以创建用户 zhumingyu,并将它密码有效期设置为 15 天为例)
2.3 案例三:创建用户并指定 UID
# useradd -u 1005 zhumingyu(补充:这里以创建用户 zhumingyu,并将它 UID 设置为 1005 为例)
2.4 案例四:创建用户并添加备注
# useradd -c "admin zhumingyu" zhumingyu(补充:这里以创建用户 zhumingyu,并将它的备注设置为 admin zhumingyu 为例)
2.5 案例五:创建用户并指定执行环境
# useradd -s /sbin/nologin zhumingyu(补充:这里以创建用户 zhumingyu,并将它的执行环境设置为 /sbin/nologin 为例)
2.6 案例六:创建用户并指定主组
# useradd -g root zhumingyu(补充:这里以创建用户 zhumingyu,并将它的主组设置为 root 组为例)
2.7 案例七:创建用户并指定从组
# useradd -G root zhumingyu(补充:这里以创建用户 zhumingyu,并将它的从组设置为 root 组 为例)
(注意:此用户的从库会同时包含 root 组和组 zhumingyu)
2.8 案例八:创建用户并指定 GID
# useradd -g 1200 zhumingyu(补充:这里以创建用户 zhumingyu,并将它的 GID 设置为 1200 为例)
2.9 案例九:创建用户并指定家目录
# useradd -d /home/zhumingyu zhumingyu(补充:这里以创建用户 zhumingyu,并指定它的家目录为 /home/zhumingyu 为例)
2.10 案例十:创建用户并不设置家目录
# useradd -M zhumingyu zhumingyu(补充:这里以创建用户 zhumingyu,但是不设置家目录为为例)
2.11 案例十一:创建用户并设置家目录
# useradd -m zhumingyu zhumingyu(补充:这里以创建用户 zhumingyu,且设置家目录为为例)
2.12 案例十二:创建用户并设置密码
# useradd -p 123 zhumingyu(补充:这里以创建用户 zhumingyu,并设置密码 123 为例)
补充一:RHEL 系统自带标准用户参考
https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/5/html/deployment_guide/s1-users-groups-standard-users
https://access.redhat.com/solutions/225183
补充二:RHEL 系统自带标准组参考
https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/5/html/deployment_guide/s1-users-groups-standard-groups