注意:
在创建 KVM 虚拟机之前要先安装 KVM 并创建 KVM 虚拟网络
镜像准备:
在 Rocky Linux 官网上下载安装系统所需要的镜像:
https://rockylinux.org/download
正文:
步骤一:理解创建 KVM 虚拟机模板的目的
主要用于批量克隆出新的 KVM 机器,节约创建新虚拟机的时间
步骤二:为这个虚拟机创建硬盘文件
2.1 创建硬盘文件
(只在真机上执行以下步骤)
# qemu-img create -f qcow2 /var/lib/libvirt/images/rockylinux9.qcow2 10G
(补充:这里以创建 10G 大小的 rockylinux9.qcow2 硬盘文件为例)
2.2 确认硬盘文件已创建
(只在真机上执行以下步骤)
# ls /var/lib/libvirt/images/ | grep rockylinux9.qcow2
(补充:这里以显示 rockylinux9.qcow2 硬盘文件为例)
步骤三:使用 KVM 和刚刚创建的硬盘文件新安装一台虚拟机
3.1 启动 KVM 的 virt-manager
(只在真机上执行以下步骤)
# virt-manager
3.2 在 virt-manager 上的左上角点击文件之后点击 “新建虚拟机”
(只在真机上执行以下步骤)
(步骤略)
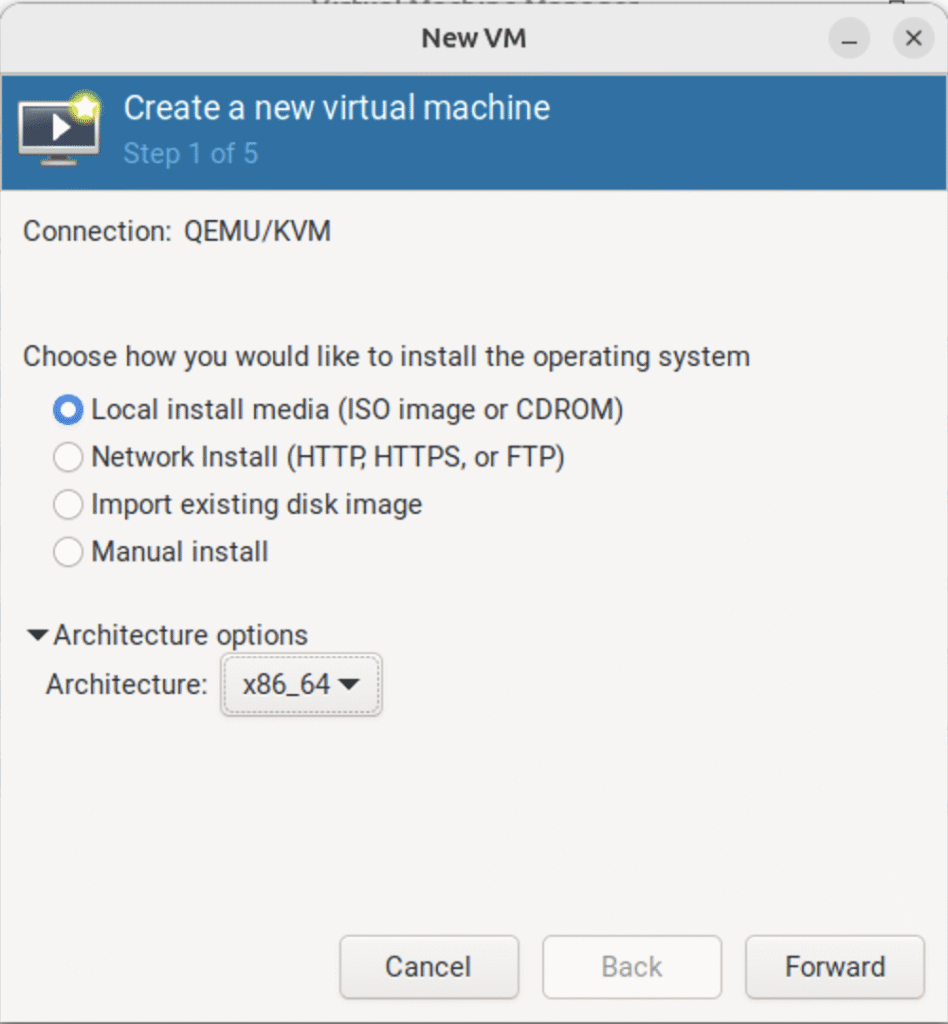
3.2.1 选择以本地安装介质的方式安装系统
(只在真机上执行以下步骤)
(图:1)
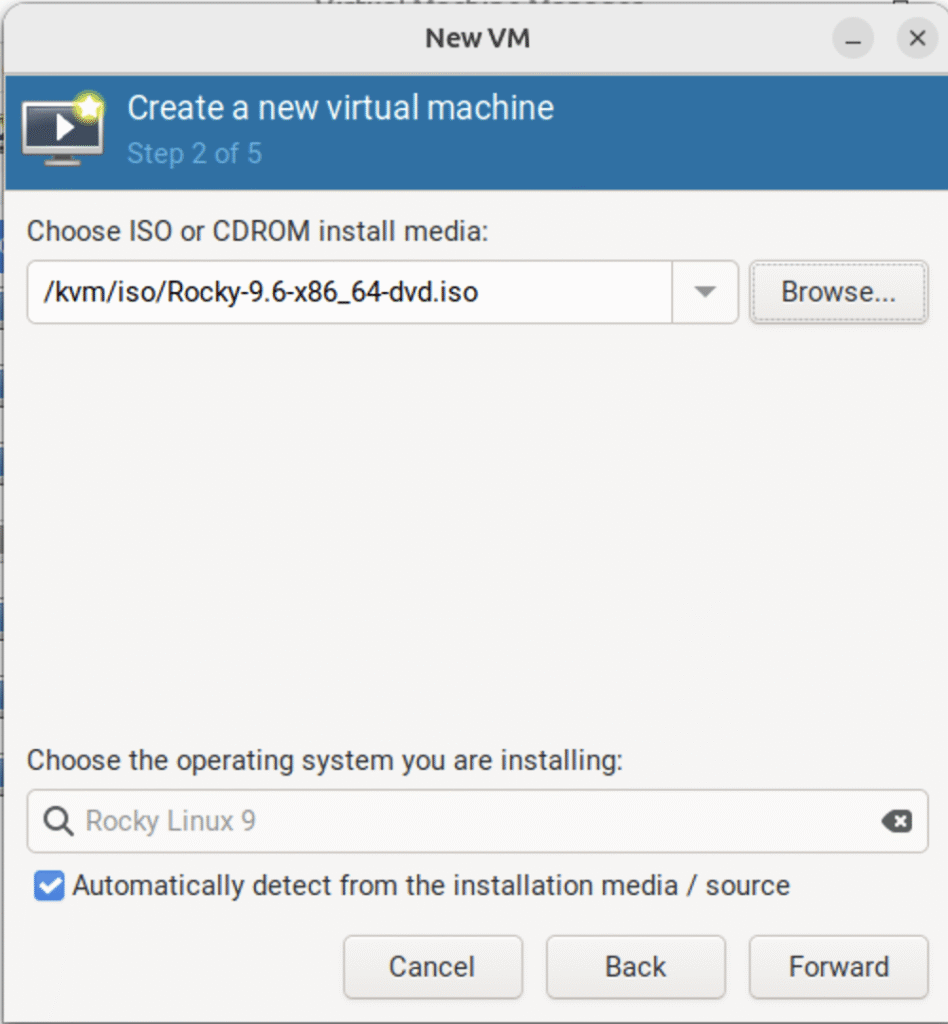
3.2.2 选择安装系统的系统镜像
(只在真机上执行以下步骤)
(图:2)
(补充:这里以使用 Rocky-9.6-x86_6-dvd1.iso 系统镜像为例)
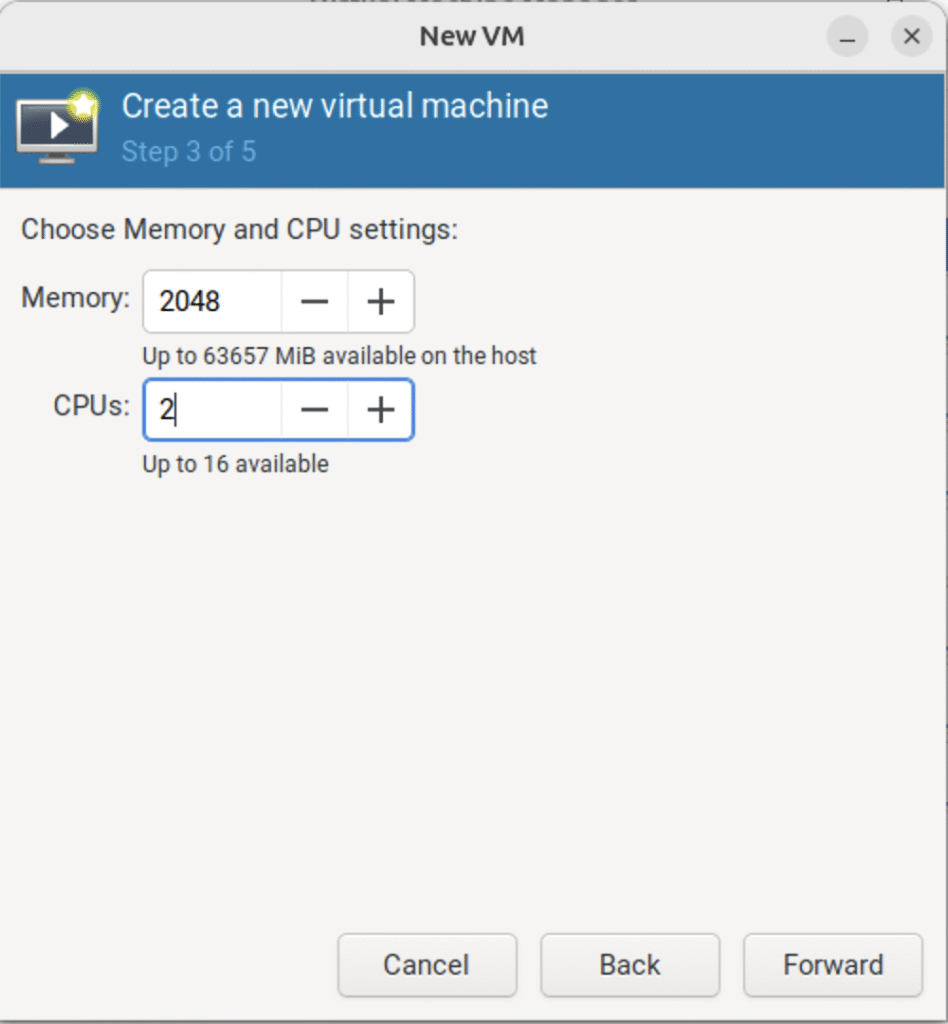
3.2.3 设置内存大小和 CPU 核心数
(只在真机上执行以下步骤)
(图:3)
(补充:这里以设置 2048 MiB 内容和 2 核 CPU 为例)
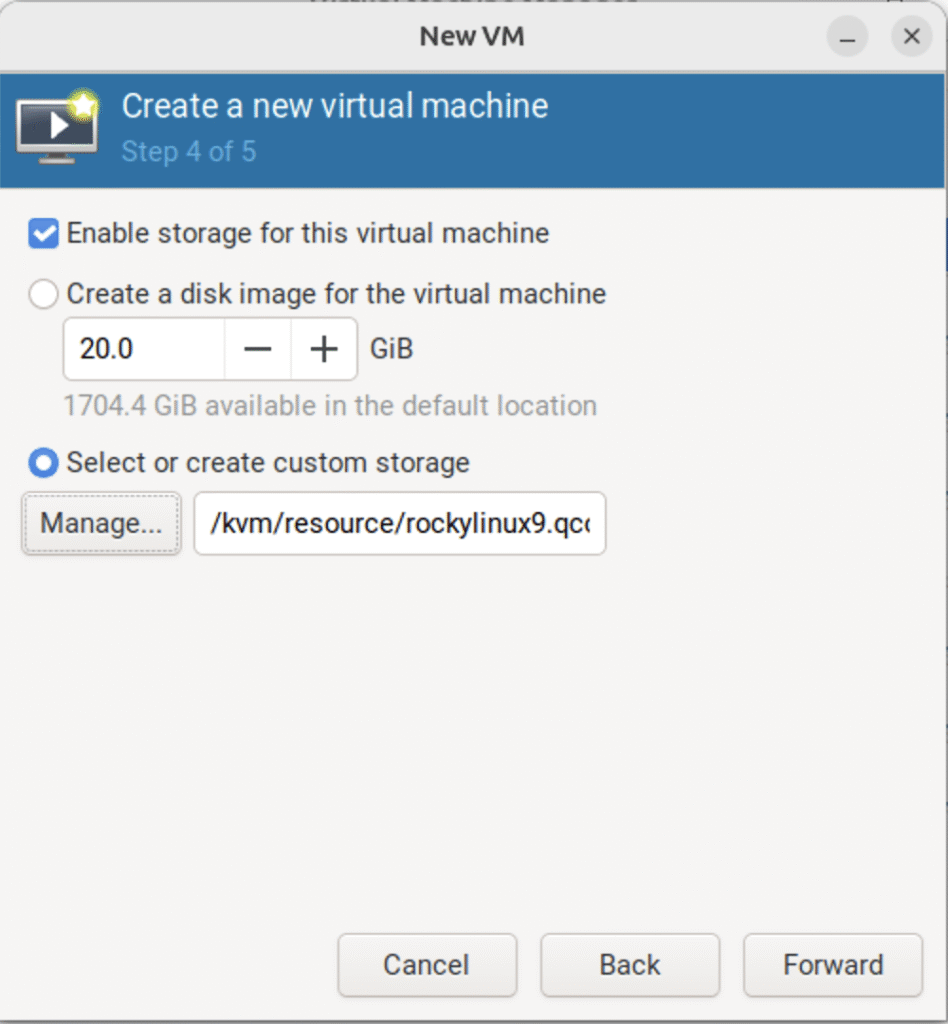
3.2.4 选择用刚刚创建的硬盘文件来安装系统
(只在真机上执行以下步骤)
(图:4)
(补充:这里以使用 rockylinux9.qcow2 硬盘文件为例)
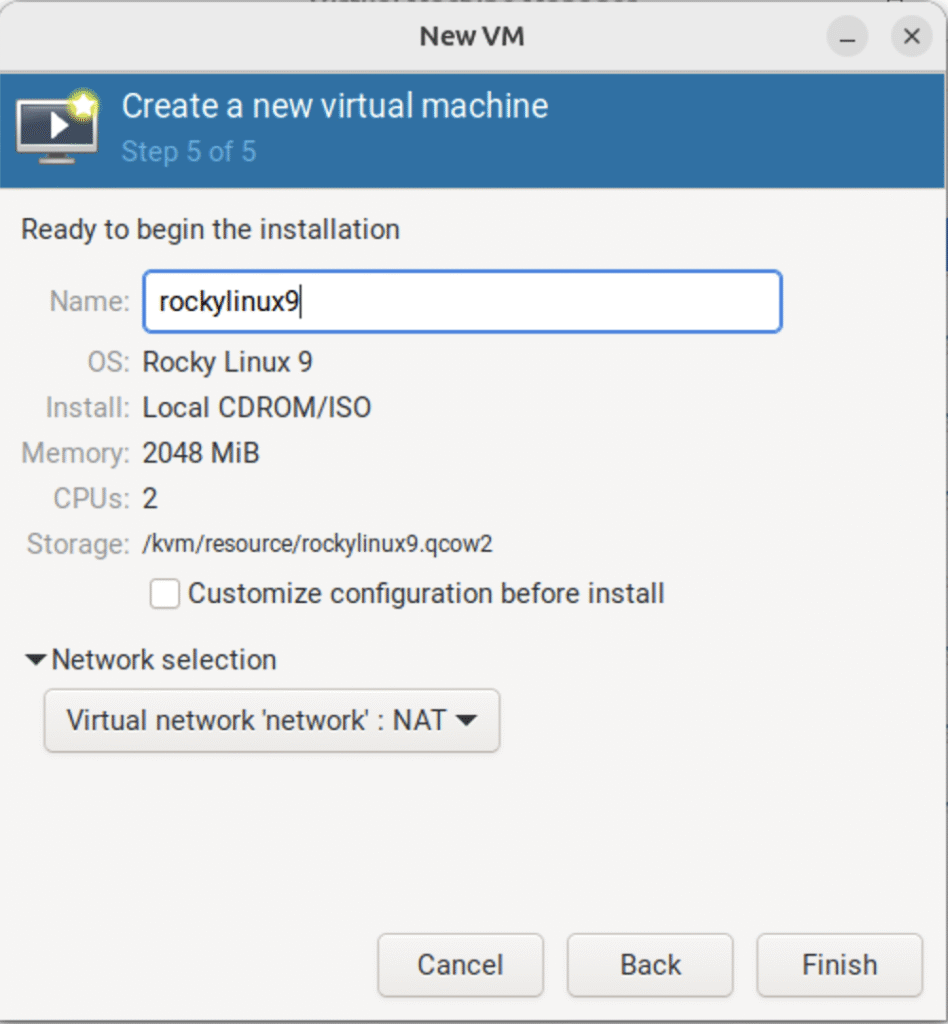
3.2.5 给虚拟机命名并选择虚拟网络
(只在真机上执行以下步骤)
(注意:虚拟网络必须提前创建好)
(图:5)
(补充:这里以将虚拟机命名为 rockylinux9 并使用 network 网络为例)
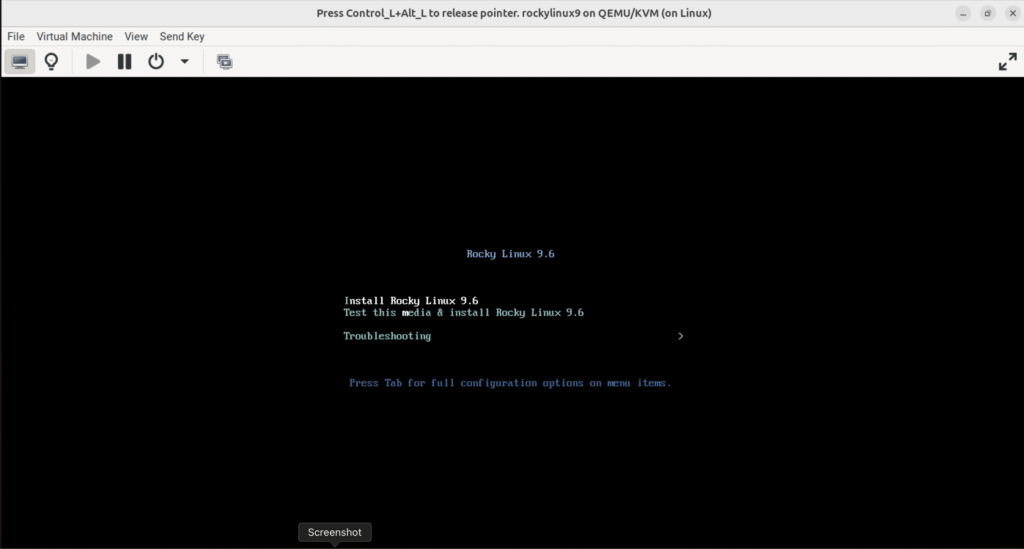
3.2.6 开始安装系统
(只在真机上执行以下步骤)
(图:6)
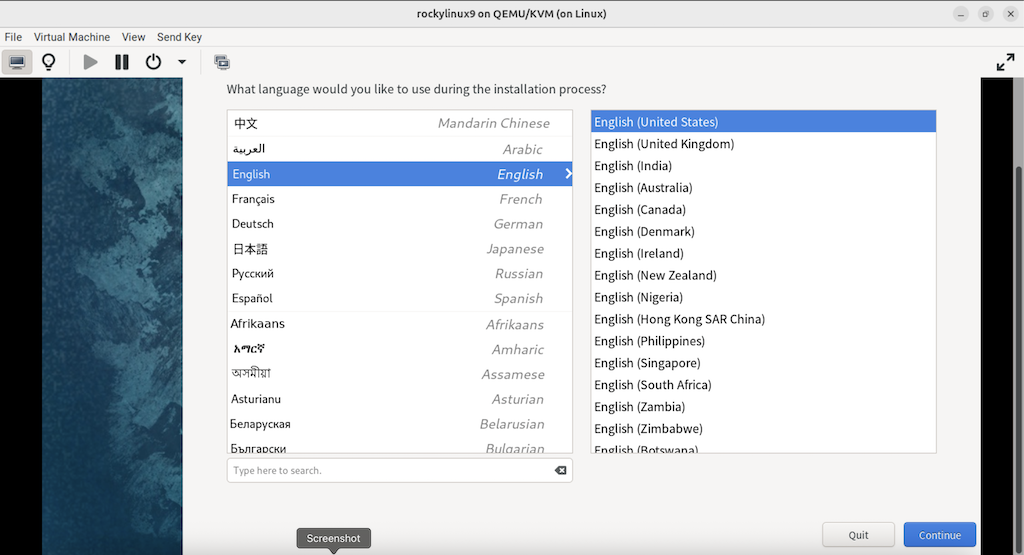
3.2.7 选择系统语言
(只在真机上执行以下步骤)
(图:7)
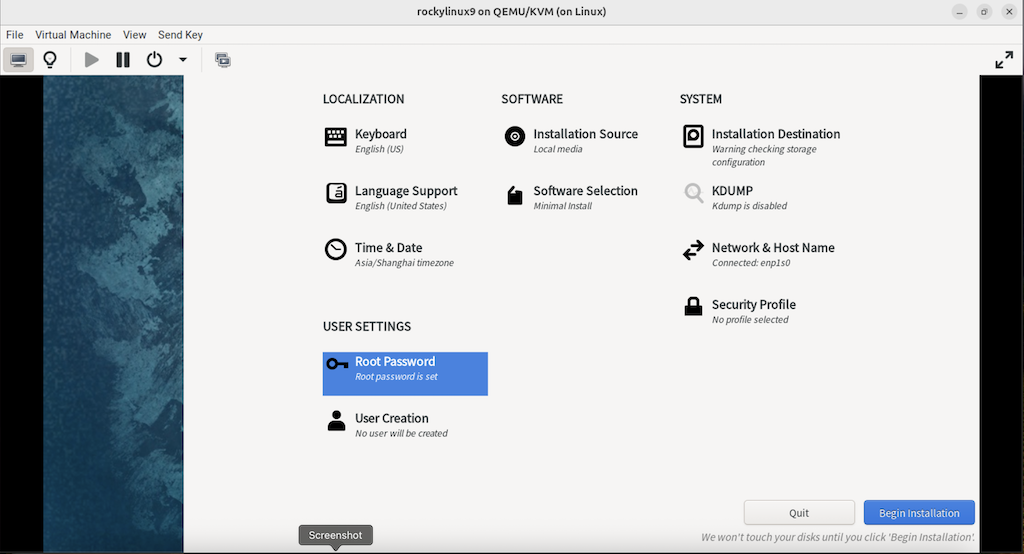
3.2.8 之后进行系统配置界面
(只在真机上执行以下步骤)
需要手动配置的地方有四个:
1) “INSTALLATION DESTINATION”
2) “KDUMP”
3) “SOFTWARE SELECTION”
4) “Root Password”
分别点击以后就可以配置了
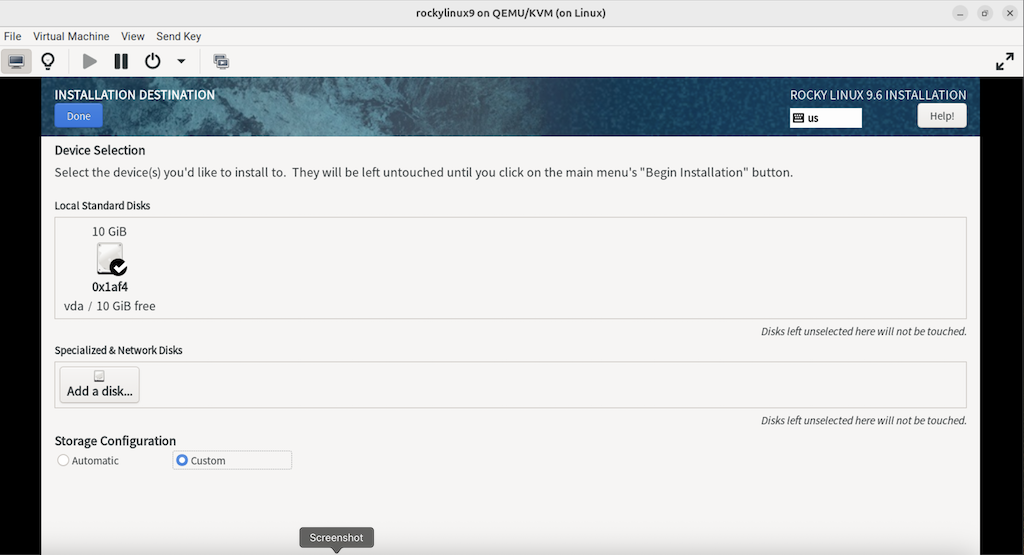
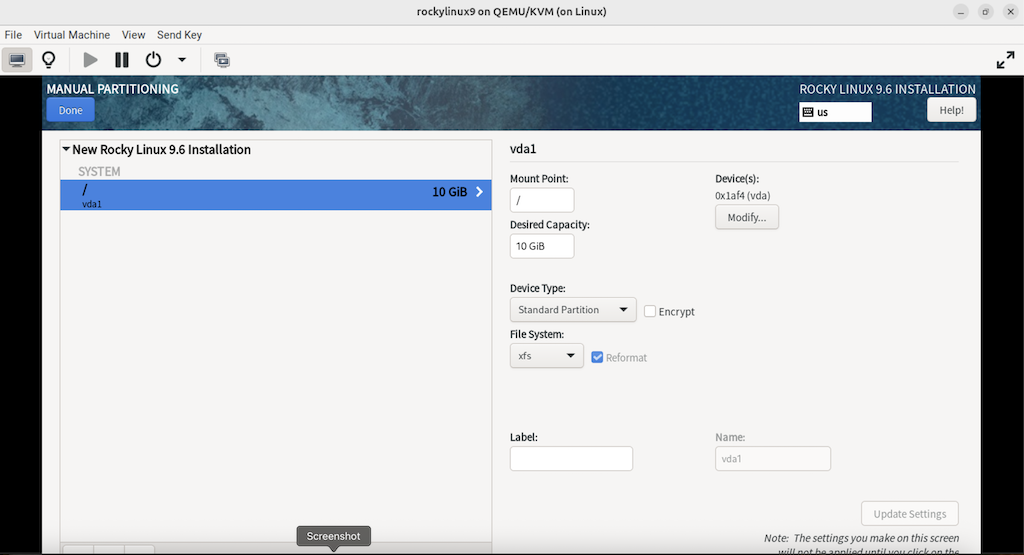
3.2.8.1 通过 “INSTALLATION DESTINATION” 对硬盘进行分区
(只在真机上执行以下步骤)
(补充:完成后点击左上角的 “DONE”)
(注意:只分一个分区,只设置一个挂载点挂载到根 “/”,使用标准硬盘类型,硬盘格式设置为 XFS)
(图:8)
(图:9)
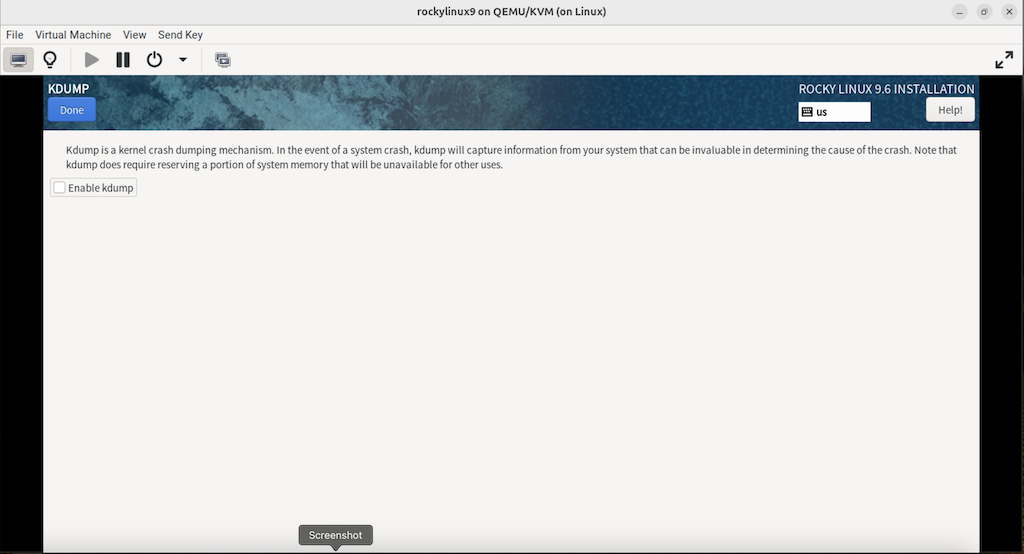
3.2.8.2 取消 “KDUMP”
(只在真机上执行以下步骤)
(补充:完成后点击左上角的 “DONE”)
(图:10)
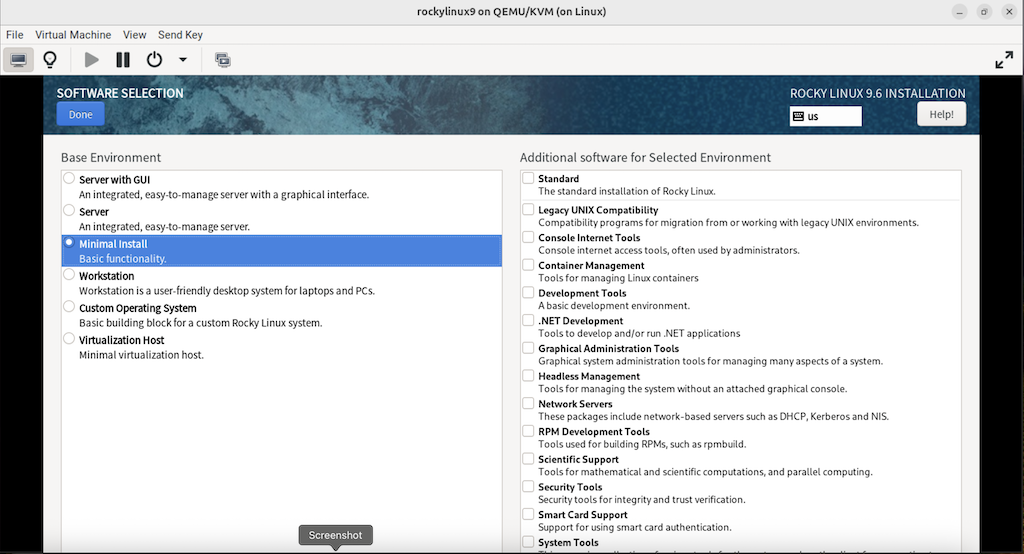
3.2.8.3 选择最小化安装系统
(只在真机上执行以下步骤)
(补充:完成后点击左上角的 “DONE”)
(图:11)
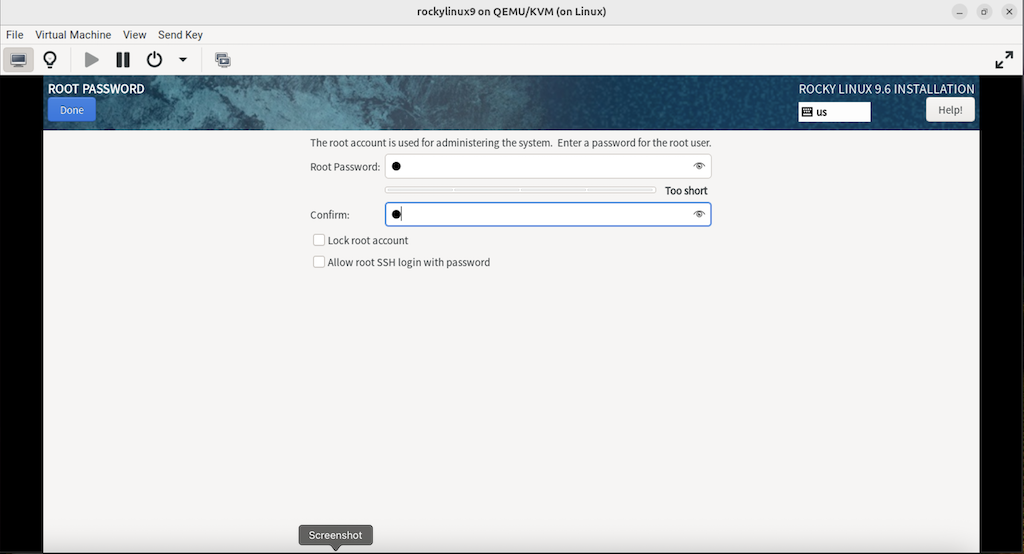
3.2.8.4 设置 ROOT 密码
(只在真机上执行以下步骤)
(图:12)
3.2.9 之后点击右下角的 “BEGIN INSTALLATION”
(只在真机上执行以下步骤)
(图:13)
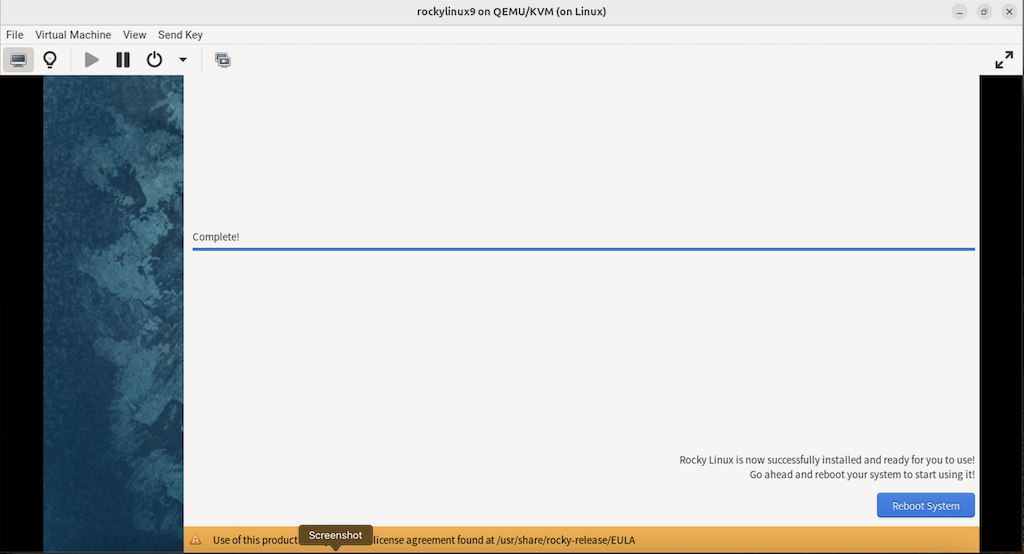
3.2.10 安装完成后重启
(只在真机上执行以下步骤)
3.2.11 在安装系统的过程中需要注意的内容总结
(只在真机上执行以下步骤)
1) 一定要使用刚刚创建的 /var/lib/libvirt/images/rockylinux8.qcow2 作为安装虚拟机的硬件文件
2) 虚拟机网络 “0” 要提前创建好
3) 只分一个分区,只设置一个挂载点挂载到根 “/”,使用标准硬盘,硬盘格式是 XFS
4) 取消 “KDUMP”
5) 选择最小化安装系统
6) 设置 root 密码
步骤四:进入新创建虚拟机修改配置
4.1 允许 root 用户远程登陆
4.1.1 修改 SSH 配置文件
# vi /etc/ssh/sshd_config
在此行下面:
......
#PermitRootLogin prohibit-password
......
添加:
......
PermitRootLogin yes
......
4.1.2 让刚刚修改的配置文件生效
# systemctl restart ssd
4.2 修改网卡个性化设置
4.2.1 修改网卡配置文件
(只在虚拟机上执行以下步骤)
# vi /etc/NetworkManager/system-connections/enp1s0.nmconnection
将全部内容修改如下:
[connection]
id=enp1s0
type=ethernet
autoconnect-priority=-999
interface-name=enp1s0
timestamp=1755516857
[ethernet]
[ipv4]
method=auto
4.2.2 使修改的网卡配置生效
(只在虚拟机上执行以下步骤)
# reboot
4.3 禁用 SELinux
(只在虚拟机上执行以下步骤)
# vi /etc/selinux/config
将全部内容修改如下:
# This file controls the state of SELinux on the system.
# SELINUX= can take one of these three values:
# enforcing - SELinux security policy is enforced.
# permissive - SELinux prints warnings instead of enforcing.
# disabled - No SELinux policy is loaded.
# See also:
# https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/9/html/using_selinux/changing-selinux-states-and-modes_using-selinux#changing-selinux-modes-at-boot-time_changing-selinux-states-and-modes
#
# NOTE: Up to RHEL 8 release included, SELINUX=disabled would also
# fully disable SELinux during boot. If you need a system with SELinux
# fully disabled instead of SELinux running with no policy loaded, you
# need to pass selinux=0 to the kernel command line. You can use grubby
# to persistently set the bootloader to boot with selinux=0:
#
# grubby --update-kernel ALL --args selinux=0
#
# To revert back to SELinux enabled:
#
# grubby --update-kernel ALL --remove-args selinux
#
SELINUX=disabled
# SELINUXTYPE= can take one of these three values:
# targeted - Targeted processes are protected,
# minimum - Modification of targeted policy. Only selected processes are protected.
# mls - Multi Level Security protection.
SELINUXTYPE=targeted
4.4 禁用空路由
(只在虚拟机上执行以下步骤)
# vi /etc/sysconfig/network
将全部内容修改如下:
# Created by anaconda
NOZEROCONF="yes"
4.5 添加 Console 配置
4.5.1 修改 GRUB 内核配置文件
(只在虚拟机上执行以下步骤)
# vi /etc/default/grub
将全部内容修改如下:
GRUB_TIMEOUT=5
GRUB_DISTRIBUTOR="$(sed 's, release .*$,,g' /etc/system-release)"
GRUB_DEFAULT=saved
GRUB_DISABLE_SUBMENU=true
GRUB_TERMINAL_OUTPUT="console"
GRUB_SERIAL_COMMAND="serial --unit=1 --speed=115200"
GRUB_CMDLINE_LINUX="biosdevname=0 net.ifnames=0 console=tty0 console=ttyS0,115200n8"
GRUB_DISABLE_RECOVERY="true"
GRUB_ENABLE_BLSCFG=true
4.5.2 使修改的 GRUB 内核配置生效
(只在虚拟机上执行以下步骤)
# grub2-mkconfig -o grub
4.6 将系统自动挂载的硬盘从使用 UUID 换成硬件路径
4.6.1 显示根 “/” 分区的 UUID
(只在虚拟机上执行以下步骤)
# blkid
/dev/vda1: UUID="682d9854-9ca6-4272-9adb-dc9bee3098f6" TYPE="xfs" PARTUUID="bf6af362-01"
(补充:这里的 UUID 是: 682d9854-9ca6-4272-9adb-dc9bee3098f6)
4.6.2 在自动挂载文件里将根 “/” 分区的 UUID 换成硬件路径
(只在虚拟机上执行以下步骤)
# vi /etc/fstab
将以下内容:
......
UUID=682d9854-9ca6-4272-9adb-dc9bee3098f6 / xfs defaults 0 0
(补充:这里的 UUID 是: 682d9854-9ca6-4272-9adb-dc9bee3098f6)
修改为:
/dev/sda1 / xfs defaults 0 0
4.7 删除不用的程序
(只在虚拟机上执行以下步骤)
# yum -y remove firewalld-* python-firewall
4.8 对虚拟系统进行升级
(只在虚拟机上执行以下步骤)
# yum -y update
4.9 进行分区扩展
4.9.1 安装分区扩展软件
(只在虚拟机上执行以下步骤)
# yum install -y cloud-utils-growpart
4.9.2 给开机自启配置文件相应的权限
# chmod 755 /etc/rc.local
4.9.3 设置开机自动扩容根 “/” 目录
(只在虚拟机上执行以下步骤)
# vi /etc/rc.local
添加以下内容:
......
/usr/bin/growpart /dev/sda1
/usr/sbin/xfs_growfs /
4.10 修改虚拟机系统的名称
(只在虚拟机上执行以下步骤)
# vi /etc/hostname
将全部内容修改如下:
rockylinux9
4.11 启用 serial 服务实现通过 virsh console 命令控制虚拟机
(只在虚拟机上执行以下步骤)
# systemctl start serial-getty@ttyS0
# systemctl enable serial-getty@ttyS0
4.12 清除虚拟系统的历史命令
(只在虚拟机上执行以下步骤)
# history -c
4.13 关闭虚拟机
(只在虚拟机上执行以下步骤)
# poweroff
步骤五:在真机上对虚拟机进行清理优化
(只在真机上执行以下步骤)
# sudo virt-sysprep -d rockylinux9
(补充:这里以清理 rockylinux9 虚拟机为例)
(
注意:如果此命令不存在
1) Rocky Linux 系统的话需要安装 libguestfs-tools
2) openSUSE 系统的话需要安装 guestfs-tools
)
步骤六:此时就可以将此虚拟机的硬件文件作为模板进行批量克隆虚拟机了
(只在真机上执行以下步骤)
(步骤略)